开云app下载 OpenClaw绝配! GPT-5.4问世, AI能力运行大一统, 等于太贵
发布日期:2026-03-09 13:14 点击次数:140

机器之心剪辑部
周五凌晨,OpenAI 负责发布 GPT-5.4,引入了一种新形态:原生的算计机使用。
有好奇艳羡好奇艳羡的是,此次 GPT-5.4 的上新,恰好发生在着名开荒者 Peter Steinberger 加入 OpenAI 不久之后。这很难不让东谈主预计,Peter 的加入会对 OpenAI 在算计机使用和开荒者器具方进取的布局产生若干影响。Peter 本东谈主也进行了宣传:
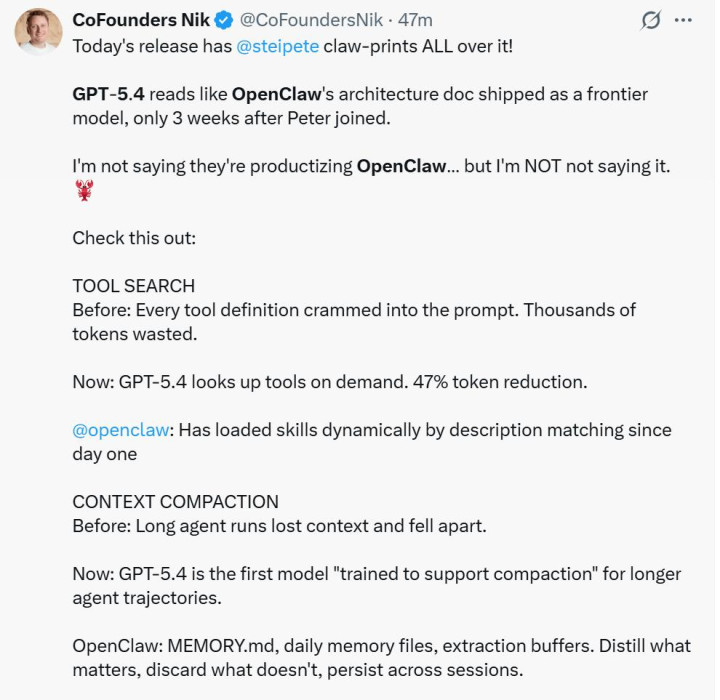
还有网友暗示:GPT-5.4 的发布,到处都有 Peter Steinberger 的「爪印」!GPT-5.4 看起来就像是 OpenClaw 的架构文档被径直作念成了一个前沿模子,而这一切发生在 Peter 加入 OpenAI 只是 3 周之后。该网友还进行了一些对比,比如以前扫数器具界说都必须塞进 prompt 里,阔绰千千万万的 token,当今是 GPT-5.4 不错按需查找器具界说,token 使用量减少 47%。而 OpenClaw 从第一天起就通过描写匹配动态加载妙技(skills)。
又比如,往时,模子自己并莫得原生能力去径直操作软件或实施完好的开荒经过。而在 GPT-5.4 中,智能体照旧不错在不同应用之间自动运行「构建 → 运行 → 考证 → 开荒」的轮回,完了较为完好的任务闭环。值得持重的是,这种责任形态与 OpenClaw 的假想非凡一样。
而这些变化,也恰巧引出了 GPT-5.4 最中枢的少许:原生算计机使用能力(Computer Use)。
新一代大模子在常识责任和网罗搜索方面判辨更出色,具备原生的算计机使用能力。GPT-5.4 当今不错径直操作软件、使用器具、浏览网页、实施责任经过,并狡计跨应用时期的复杂任务,最多可处理 100 万个高下文 token。
推理 + 编码 + 智能体 + 算计机适度,皆备和会在吞并个前沿模子里。
咫尺,GPT-5.4 已在 OpenAI 的 API 和 Codex 中提供,并正在 ChatGPT 中渐渐推出(面向 ChatGPT Plus、Team 和 Pro 用户灵通),取代了 GPT-5.2 Thinking 模子。OpenAI 也在 ChatGPT 和 API 中推出了 GPT-5.4 Pro(面向 Pro 和企业版用户灵通),其专为那些但愿在复杂任务中完了极致性能的用户假想。
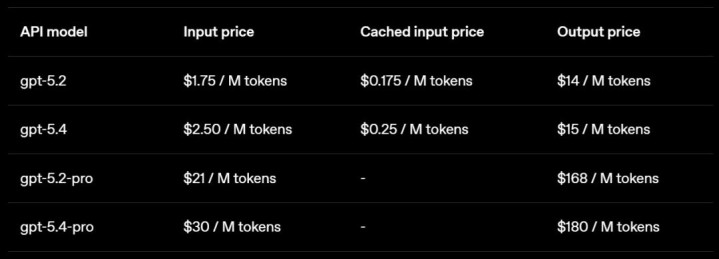
在 API 中,GPT-5.4 的 token 价钱高于 GPT-5.2,批量处理和纯真处理的价钱为设施 API 费率的一半,而优先处理的价钱为设施 API 费率的两倍。
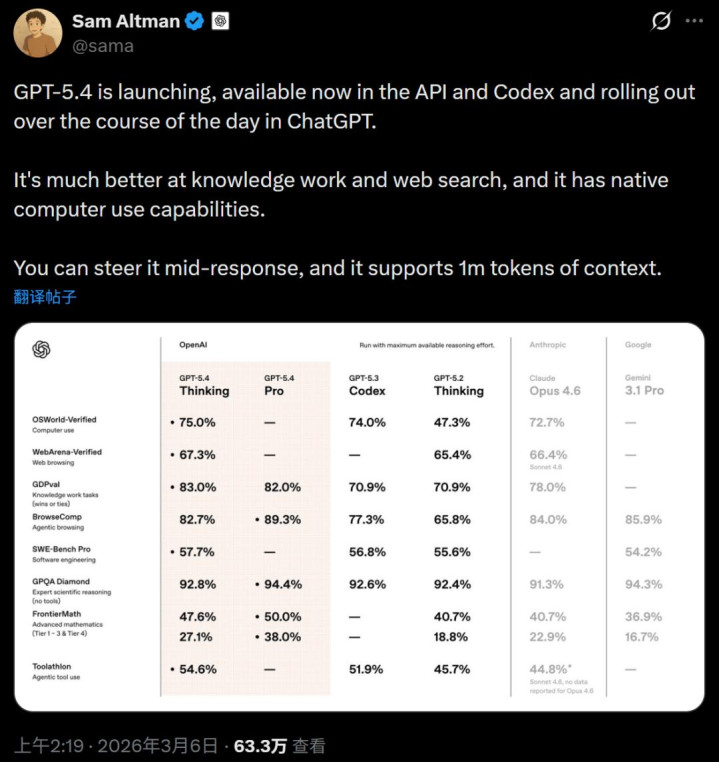
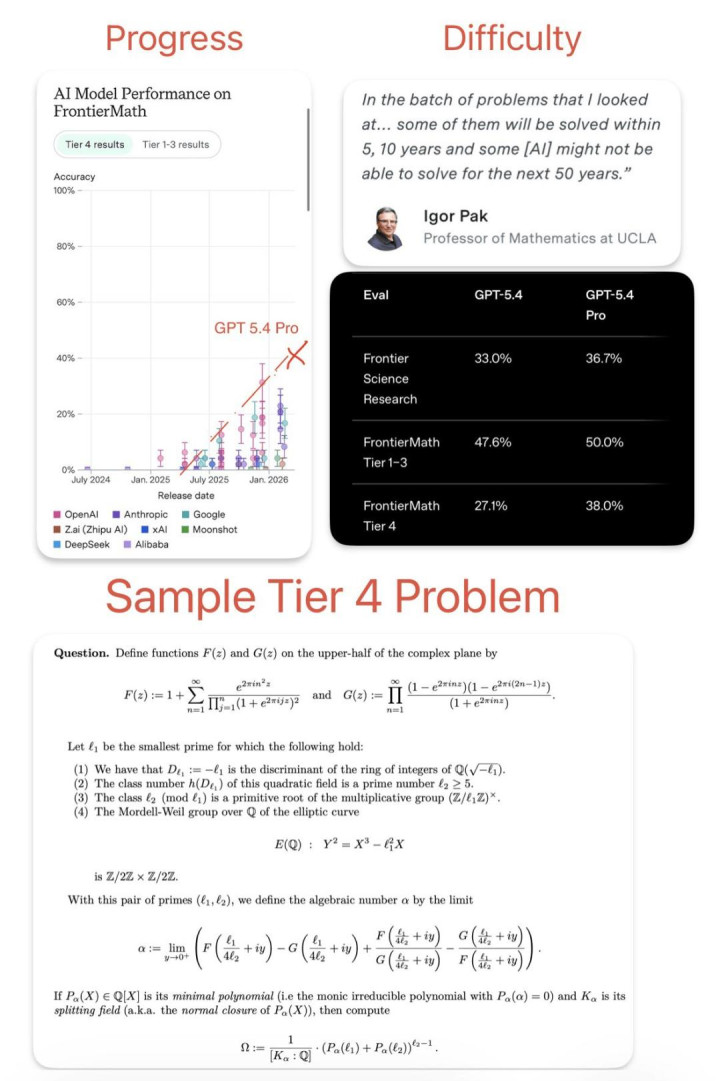
在评测基准上,GPT 5.4 Pro 以 38% 的成绩唐突打败了最难的数学基准测试 FrontierMath Tier 4—— 该基准包含 50 谈辩论级别的数学题,数学家可能需要几周时候才能搞定。只是在一年前,最好成绩为 2% (o3) ,咫尺最好的开源模子分数为 4.2% (Kimi K2.5)。
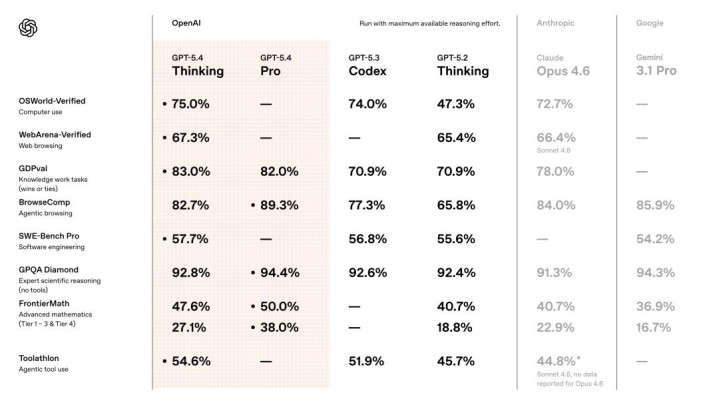
当作通用模子,GPT-5.4 具备原生的算计机使用能力,这关于开荒者和智能体而言是一次首要飞跃。
OpenAI 暗示,新模子能在多样算计机责任负载下保抓高性能。它非凡擅长编写代码来操作算计机(举例通过 Playwright 等库),也能把柄屏幕截图发出鼠标和键盘大喊。它的活动不错通过开荒者音书进行适度,这意味着开荒者不错把柄特定用例退换其活动。开荒者致使不错通过指定自界说证据战术来确立模子的安全活动,以安妥不同的风险承受能力。
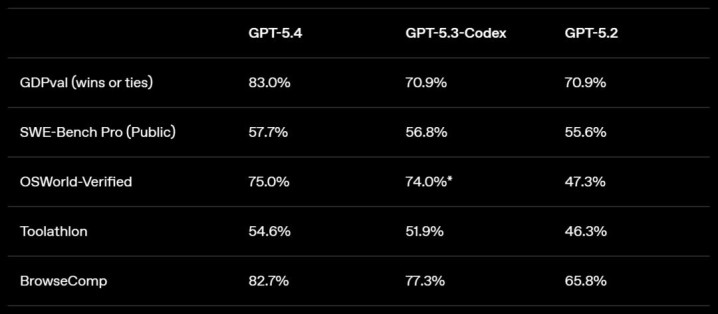
该模子的性能和纯真性体当今各项基准测试中,在 OSWorld-Verified 测试中,该测试通过屏幕截图和键盘 / 鼠标操作来揣测模子在桌面环境中导航的能力,GPT-5.4 取得了 75.0% 的当先得胜率,远超 GPT-5.2 的 47.3%,也超越了东谈主类的 72.4%。
{jz:field.toptypename/}
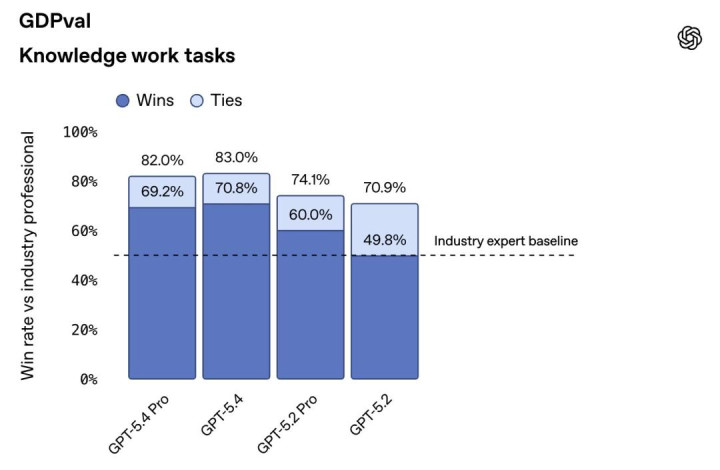
在 GDPval 测试中,GPT-5.4 在 83.0% 的比较中达到或越过了行业专科东谈主士的水平,而 GPT-5.2 的这一比例为 70.9%。
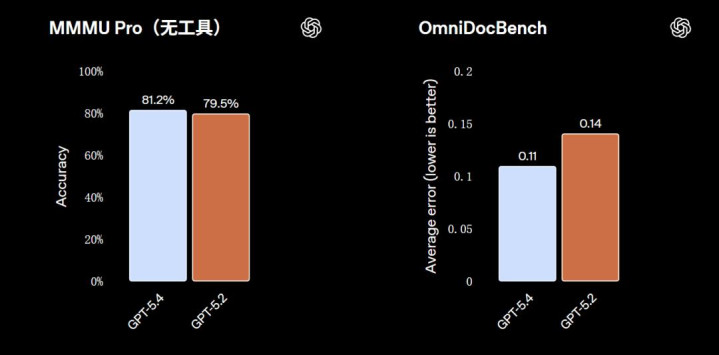
GPT-5.4 算计机性能的提高收货于其增强的通用视觉感知能力。在 MMMU-Pro 测试中,GPT-5.4 在不使用任何器具的情况下取得了 81.2% 的得胜率,优于 GPT-5.2 的 79.5%。
视觉感知能力的提高也体当今其文档领路能力的增强上。在 OmniDocBench 测试中,GPT-5.4 在不使用任何推理器具的情况下,平均罪举止 0.109,优于 GPT-5.2 的 0.140。
代码生成方面,GPT-5.4 聚首了 GPT-5.3-Codex 的编码上风,并具备当先的常识处理和算计机使用能力,这在万古候运行的任务中尤为遑急,开云app下载因为模子不错摆布器具、迭代并鼓励责任,从而减少东谈主工阻抑。在 SWE-Bench Pro 测试中,GPT-5.4 的性能与 GPT-5.3-Codex 抓平或更优,同期在推理过程中延长更低。
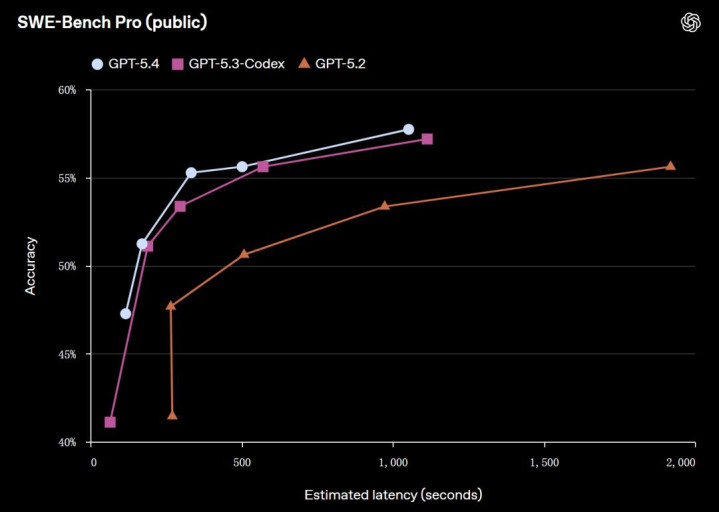
启用 Codex 中的 /fast 形态后,GPT-5.4 的 token 处理速率最高可提高 1.5 倍。它吸收的是疏通的模子和智能,只是速率更快。这意味着用户不错更灵通地完成编码任务、迭代和调试,保抓高效的责任经过。
使用 GPT-5.4 生成的 RPG 游戏,经过多回合迭代开荒。
把柄一个通俗的提醒,制作的金门大桥飞动体验。

https://mp.weixin.qq.com/s/ZELwUixswcmWUULx7Urvww?click_id=28
在 API 中,GPT-5.4 引入了器具搜索功能。这使得模子大概在领有稠密器具的情况下高效运行。
以前,当给模子分拨器具时,扫数器具的界说都会事前包含在申请申请中。关于领有遍及器具的系统,这可能会在每个申请中增多数千致使数万 token,从而增多资本、镌汰反映速率,并使高下文信息过于拥堵,而这些信息模子可能始终不会用到。
通过器具搜索,GPT-5.4 会收到一个轻量级的可用器具列表以及相应的器具搜索功能。当模子需要使用某个器具时,它不错查找该器具的界说,并将其添加到面前的对话中。
这种方法权贵减少了器具密集型责任经过所需的 token 数目。它还使智能体大概可靠地与规模更大的器具生态系统协同责任。关于可能包含数万个器具界说令牌的 MCP 办事器而言,服从提高可能非凡权贵。
OpenAI 评估了 Scale 的 MCP Atlas 中的 250 项任务,器具搜索确立在保抓疏通准确率的同期,将总 token 使用量减少了 47%。

GPT-5.4 改良了器具调用,使其在推理过程中(尤其是在 API 调用中)大概更准确、更高效地决定何时以及怎么使用器具。与 GPT-5.2 比较,它在 Toolathlon 测试中以更少的回合数完了了更高的准确率。
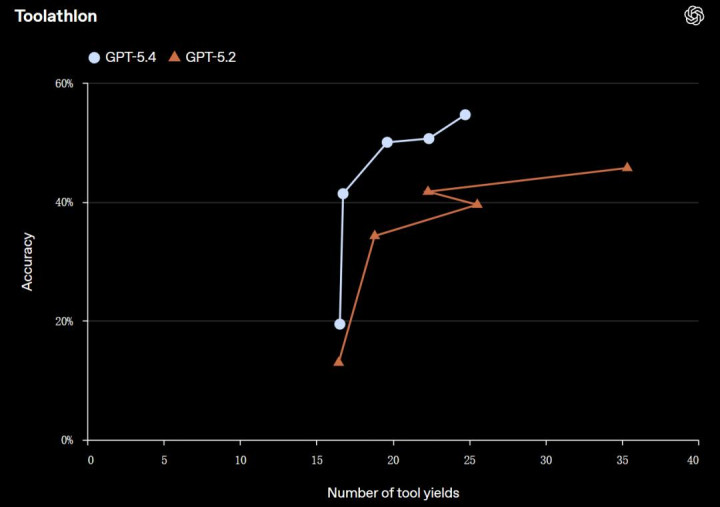
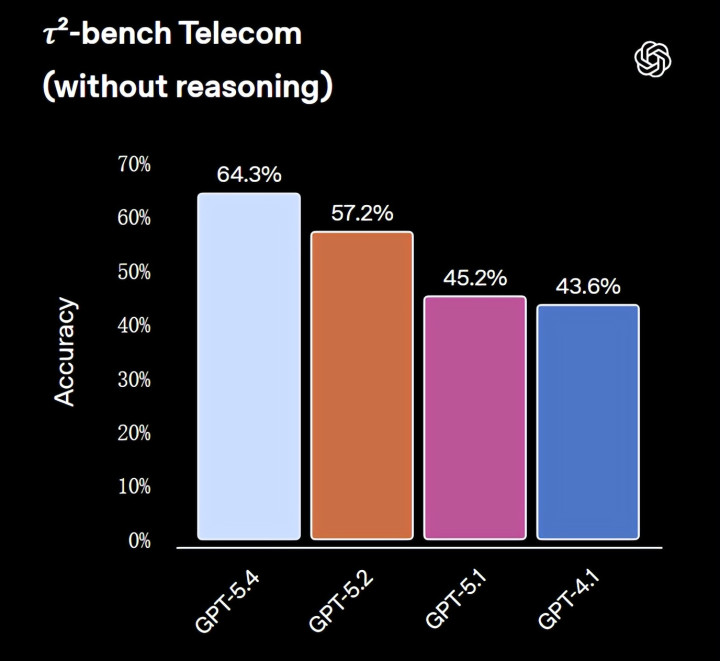
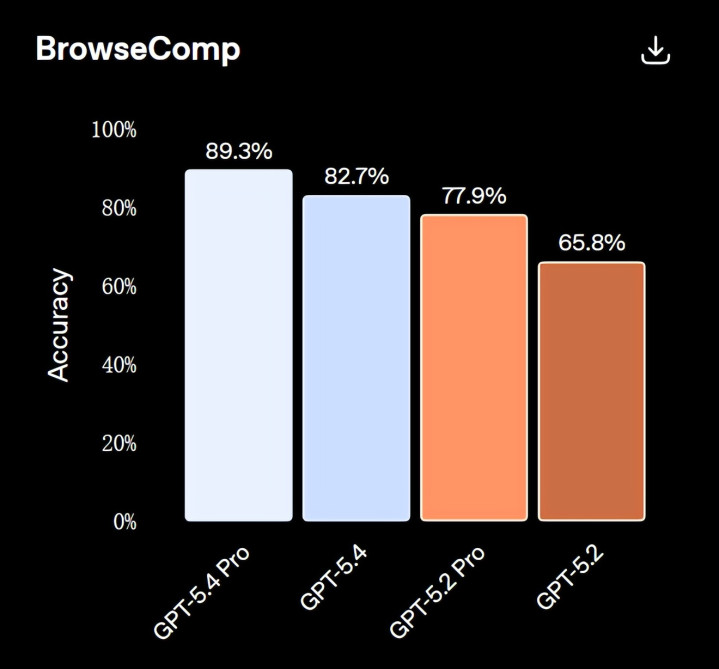
GPT-5.4 在自主网罗搜索方面也判辨更佳。在 BrowseComp 测试中,GPT-5.4 比 GPT-5.2 提高了 17% 而 GPT-5.4 Pro 则达到了 89.3%,创下了新的最高水平。
这意味着 GPT-5.4 Thinking 更擅长回复需要整合网罗上多个信息源的问题。它不错更抓久地进行多轮搜索,以识别最有关的信息源,尤其适用于「大海捞针」式的问题,并将它们空洞成了了、论证充分的谜底。
在 ChatGPT 中,GPT-5.4 Thinking 当今不错事前提供其想考观点,你不错在它运行过程中随时退换地点,最终无需很是迭代即可得到更恰当需求的谜底。GPT-5.4 Thinking 还改良了深度网罗搜索,尤其是在处理高度具体的查询时,同期大概更好地保留需要万古候想考的问题的高下文信息。这些改良共同作用,意味着大概更快地得到更高质料、更贴合面前任务的谜底。
在 Codex 和 API 中,GPT-5.4 是首个具备原生、开端进的算计机使用能力的通用模子,它使智能体大概操作算计机并在多样应用时期中实施复杂的经过。GPT-5.4 还通过器具搜索功能改良了模子在大型器具和相连器生态系统中的运行神志,匡助智能体更高效地找到并使用合适的器具,同期又不舍弃智能水平。
GPT-5.4 亦然咫尺 OpenAI token 服从最高的推理模子,与 GPT-5.2 比较,它搞定问题所需的 token 数目权贵减少,这意味着更少的用度和更快的速率。
聚首通用推理、编码和专科常识责任的高出,GPT-5.4 大概完了更可靠的智能体、更快的开荒者责任经过以及 ChatGPT、API 和 Codex 的更高质料输出。
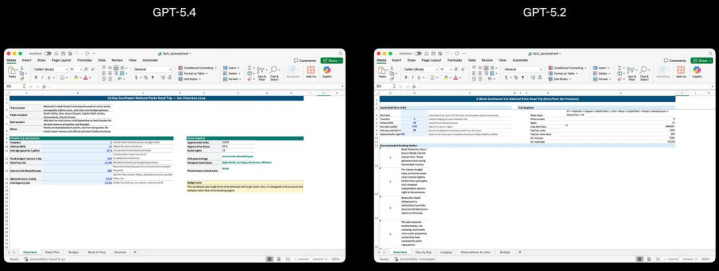
OpenAI 重心提高了 GPT-5.4 创建和剪辑电子表格、演示文稿和文档的能力。在一系列演示文稿评估提醒中,由于 GPT-5.4 的演示文稿具有更强的好意思不雅性、更丰富的视觉后果以及更高效的图像生得胜能,得到了东谈主类评分者的嗜好。
OpenAI 辩论科学家,德扑 AI Libratus 的发明者 Noam Brown 暗示,GPT-5.4 在算计机应用和经济价值任务(举例 GDPval)上已取得了庞大高出。鉴于此,科学家们觉得东谈主工智能的发展出路广袤,瞻望本年内 AI 能力将不时大幅提高。
时期的指数增长还在不时。有东谈主暗示,ChatGPT 很快就会比最好的盘问公司、最好的投资银行和最好的讼师事务所都更出色。
临了,好多东谈主照旧在使用 GPT-5.4 尝试多样任务了,不知谈新一代模子具体判辨怎么。

有东谈主照旧觉得,GPT-5.4 Pro 达到了 AGI 级别的智能。当今,你有什么 AGI 级别的问题要问吗?
- 上一篇:开云app官方下载 被狗咬了,怎么正确处理?
- 下一篇:没有了
 备案号:
备案号: